



The proposed methodology combines KG technology with an ANN to improve the chatbot’s knowledge, classification, and response generation. The process begins with data collection from a central Korean bank, spanning a three-year period from January 2018 to December 2020. This dataset comprises 34,089 chatbot log records and 317,438 customer service call logs, focusing on four primary financial products and services. Once the data collection is done, the data undergoes preprocessing using a Text-to-GraphQL technique, which converts customer queries into a graph-based format. This enables the system to identify meaningful relationships and represent them as entities and connections within the knowledge graph. The Knowledge Graph Completion (KGC) model is then applied to predict missing links and strengthen the semantic structure of the data. These outputs are transformed into the ANN framework, which is structured to analyse and classify service types based on emotional, informative, and trust-related features. The ANN consists of four sub-models, each handling features such as social attraction, emotional credibility, emotional connection, and buying intention. This enables the model to accurately classify the precise outcomes of user intent and service needs. The complete architecture and data flow of the model are illustrated in Fig. 1 of the study.

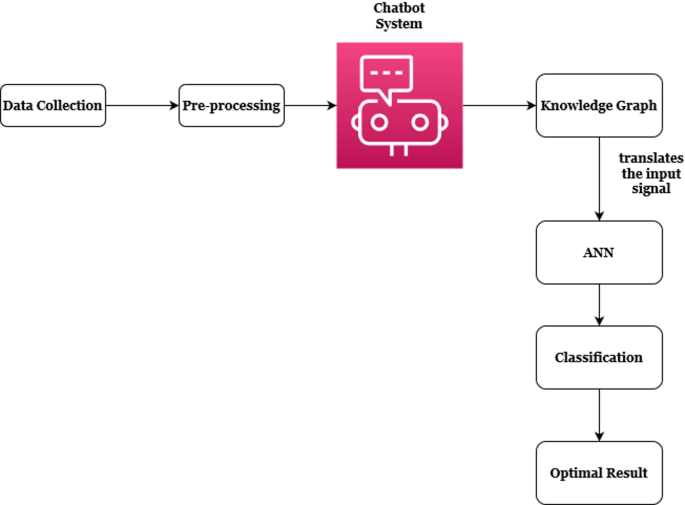
Architecture of proposed method.
Data collection
To investigate the impact of customer goods and services expenditures on bank profits (return rate rise) through two channels utilising ARS, this study analysed product information from a major Korean banking firm. The simulation dataset is adapted from6. Based on client information and the statistically significant nature of each channel’s contribution to bank profitability, we examined banking services and goods made available through chatbots or customer care phone calls. We believe that banks will be able to develop stable financial measures with the aid of our analyses. Additionally, we hope to objectively determine how much the customer care departments of all financial institutions, especially financial institutions, can be replaced by AI-based chatbots. From January 2018 to December 2020, when the chatbot was initially implemented at Bank A, we acquired 34,089 personal records of four essential items and services sold through this channel from this financial institution. Additionally, we gathered 317,438 unstructured voice recordings based on similar items from customer service. We could organise the unorganised information using a text conversion method, a Knowledge Graph, and a conversion methodology. All conditions were identical, except that each of the four goods was handled by either a chatbot or a customer support representative; it is safe to infer that the statistical effect is predictable.
Tables 2,3 and 4, which categorises each channel-product group specifically, shows roughly 9.5 times as many customers who bought products via customer support as those using the chatbot among every customer who bought financial services using the Automatic Response System (ARS). As a result, 92.3% of the information about the parameters made purchases via intermediaries, while just 9.8% used chatbots. Regarding age categories, senior citizens (55.2%) are more likely than younger people (45.8%) to purchase products and services through excellent customer service. All four of the goods supplied through customer service follow the same pattern. Notably, the disparity increases by 14.8%, or almost 5% more than the median of 9.57%. 55.9% of those who purchase goods use support services to pay their utility bills.
The above statistical data mentioned in Tables 2,3 and 4 is used for evaluation. The proposed method classifies the products based on customer service and chatbot users.
Knowledge graph for translating an input data
The knowledge graph method utilises Text-to-Graph Query Language (QL), which enables the translation of user or customer queries into a graphical structure. It transforms customer language queries into logical representations and makes it suitable for further processing. The primary task of the model is to address a multi-class classification problem, where customer service queries are categorised into predefined service types such as ‘loan inquiry’, ‘bill payment’, ‘investment support’, and ‘credit score assistance. The knowledge graph is often developed on top of the current modules in the proposed chatbot to link all retrieved data, combine structured and unstructured information, and display it to the user as a legitimate knowledge panel in a structured and understandable manner.
A knowledge graph \(K=\left(_,_,{e}_{k}\right)\) is a collection of triplets where \({e}_{i}\) and \({e}_{k}\) denote the entities, rj represents the relation between them; accordingly, provided a set of entities \(E\) and a set of relationships \(R\). We typically refer to \({e}_{i}\) and \({e}_{k}\) as the head of the item \({h}_{i}\) and tail \({t}_{k}\) of the triplet. A third-order binary tensor, known as the adjacency tensor of \(K\), termed \(X\in 0, 1 | E\) || R || E |, can identify a knowledge graph’s identity. If \(({h}_{i},{r}_{j},{t}_{k})\) is true, then \({X }_{ijk}= 1\); otherwise, \({X }_{ijk}= 0\).
Knowledge graph (KG)
Using known triplets in \(K\), KG attempts to foresee legitimate but unseen triplets. To correlate a score \(s({h}_{i},r,{t}_{k})\) with each possible triplet \(({h}_{i},r,{t}_{k})\), KG systems construct a score function s: \(E\times R\times E\to R\). The scores reflect the likelihood of triplets. KGC models first fill in the blanks for every entity in the knowledge graphs for queries like \(({h}_{i},{r}_{j},?)\) or \((?,{r}_{j},{t}_{k})\), and then they grade the resulting triplets. Valid triplets should perform better than invalid triplets, according to expectations.
Modern KG models include knowledge graph embedding (KGE) designs that connect every item (whether it’s a head or tail organization, \({e}_{i}\in E\)) and relation \(({r}_{j}\in R)\) to an embedded \({e}_{i}\) and \({r}_{j}\) on carefully chosen embedding spaces. Then, they immediately create an evaluation mechanism to simulate how relationships and entities behave. Following is a review of three typical KGE models.
TransE uses Minkowski lengths f+or establishing function scores in the actual world. The scoring function is particularly given its embeddings \(h, r, and t.\)
$$f\left(h,r,t\right)=f(h,r,t=-||h+r-t|{|}_{\raisebox{1ex}{$1$}\!\left/ \!\raisebox{-1ex}{$2$}\right.})$$
(1)
where 1/2 denotes that the distance might be either L1 or L2.
DistMult provides functions for scoring on the actual space using the inner product. Notably, the function that scores is given the embeddings \(h, r\), and \(t\).
$$f\left(h,r,t\right)={h}^{T}diag(r)\cdot t$$
(2)
here \(r\) is a diagonal matrix formed from the relation vector \(r\) and \(h\) and \(t\) are entity embeddings.
ConvE uses convolutional neural networks to specify scoring algorithms. The evaluation mechanism is a
$$\sigma (vec(\sigma \left[\overline{r },\overline{h }\right]*\omega )W{)}^{T}t$$
(3)
An activating operation, a 2D convolution, a filter used in convolutional layers, a 2D shape for real vectors, \(\sigma\) is the activation function, ω is the convolutional kernel, and W is a trainable matrix of weights, respectively.
Figure 2 shows the structure of Knowledge Graph Completion.


KG-ANN for classification
We utilized the ANN to identify potential non-linear relationships and rank the significance of each component after examining the causal connection through KG. According to previous studies, the input neurons in ANN models can only be significant independent variables. The four endogenous components of the KG-ANN model (such as social interest, psychological trustworthiness, emotional connection, and buying intention) led us to partition the framework into four neural network models. Three inputs of emotional, informative, and reputational support and one output of social attraction are considered as Model A. Three inputs (emotional, informational, and esteem support) and one outcome (emotional credibility) are present in Model B. Social attractiveness and emotional credibility is two inputs in Model C, and emotional connection is one outcome. Lastly, model D has a single output (buying intention) and two inputs (social attraction and affective believability). The four ANN models used in this investigation are depicted in their architecture in Fig. 3.


Structure of proposed KG-ANN method.
$${net}_{j}^{h}=\sum_{i=1}^{l+1}{W}_{ji}\cdot {x}_{i} and {y}_{j}=f({net}_{j}^{h})$$
(4)
$${net}_{k}^{o}=\sum_{j=1}^{J+1}{V}_{ki}\cdot {y}_{j} and {O}_{k}=f({net}_{k}^{o})$$
(5)
$$f\left(net\right)=\frac{1}{1+{e}^{-\lambda net}}$$
(6)
$$SSE=\frac{1}{2P}{\sum }_{p=1}^{P}{\sum }_{k=1}^{K}{({d}_{pk}-{o}_{pk})}^{2}$$
(7)
It is shown in Eqs. (4) and (5) \({W}_{ji}\) is the weight between \(ith\) input neuron and \(jth\) hidden neuron and \({V}_{kj}\) denotes weight between the \(jth\) hidden neuron and \(kth\) output neuron, respectively, \({x}_{i}\) is the input to the network and \({y}_{j}\) is the output of hidden neuron \(j\) and finally \({O}_{k}\) is the output of the neuron \(k\). Equation (6) shows that a typical sigmoid function is increasing monotonically and capable of differentiation, with values ranging from 0 to 1;
The SSE (sum square of error) formula is given in Eq. (7), where \({d}_{pk}\) denotes the desired outcome of neuron \(k\) and \({o}_{pk}\) is the actual output of the neuron \(k\) with respect to input pattern \(p\); \(P\) is the total number of input patterns and \(K\) is the total number of output neurons.
link